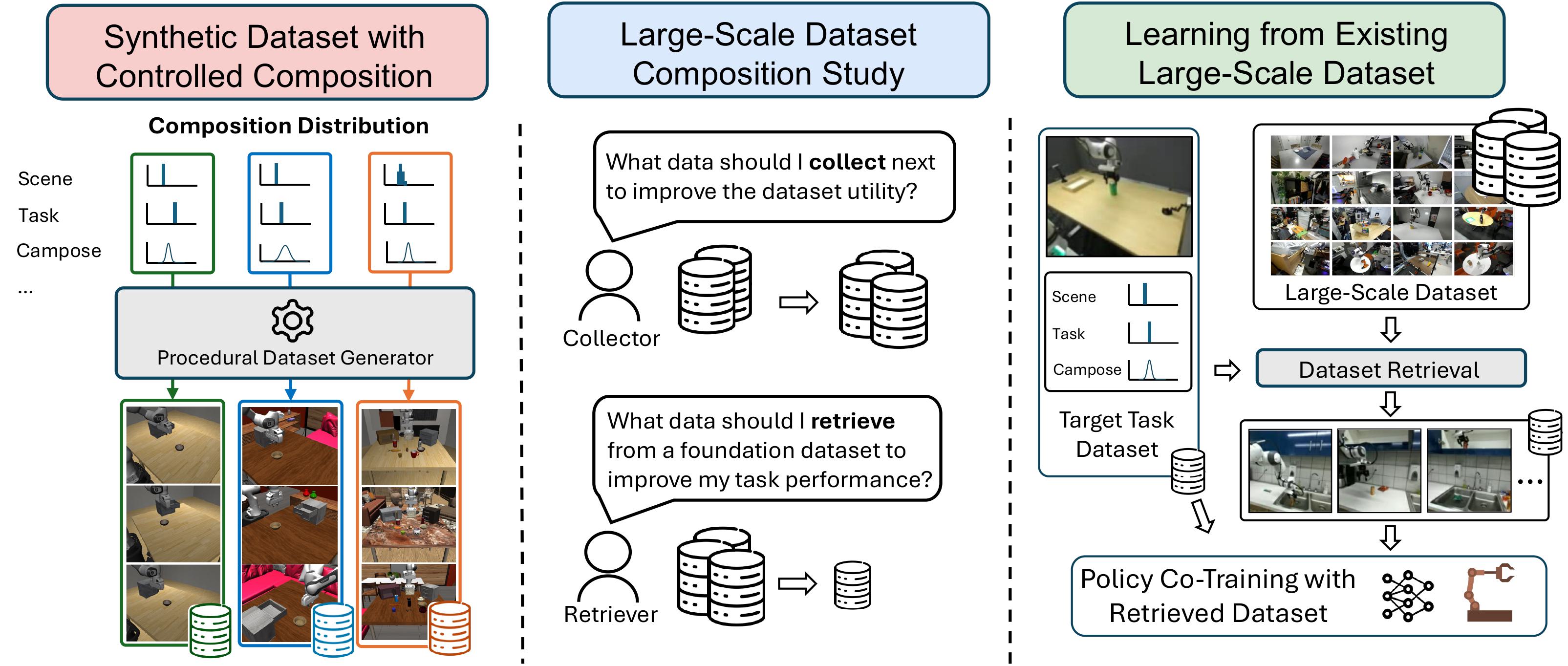
Below are some videos showing rollouts for different tasks, with different co-training datasets retrieved from the DROID dataset.
We retrieve datasets to train robot policies for the following target tasks:
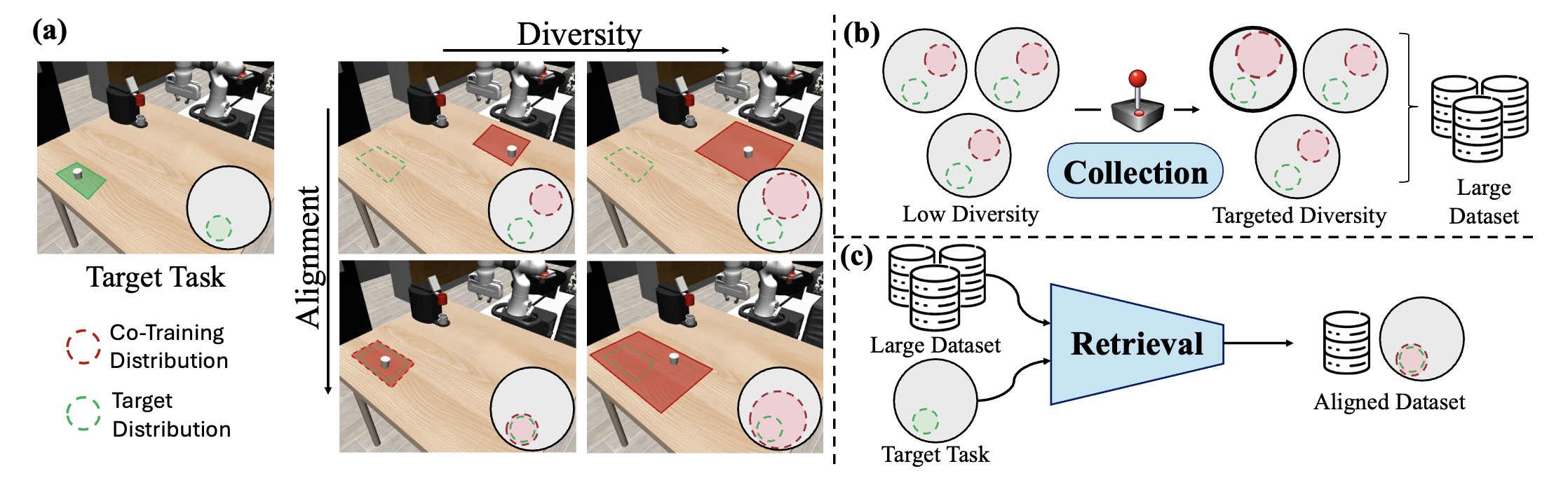
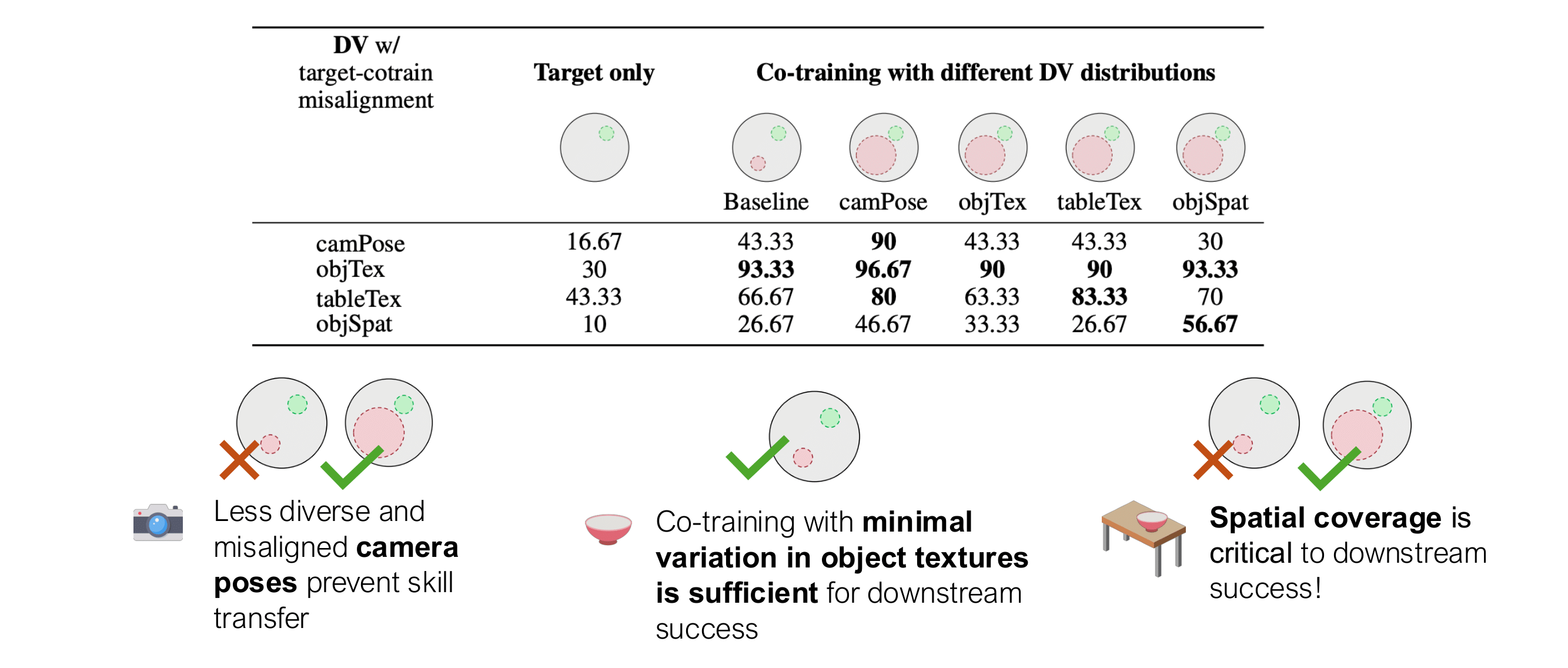
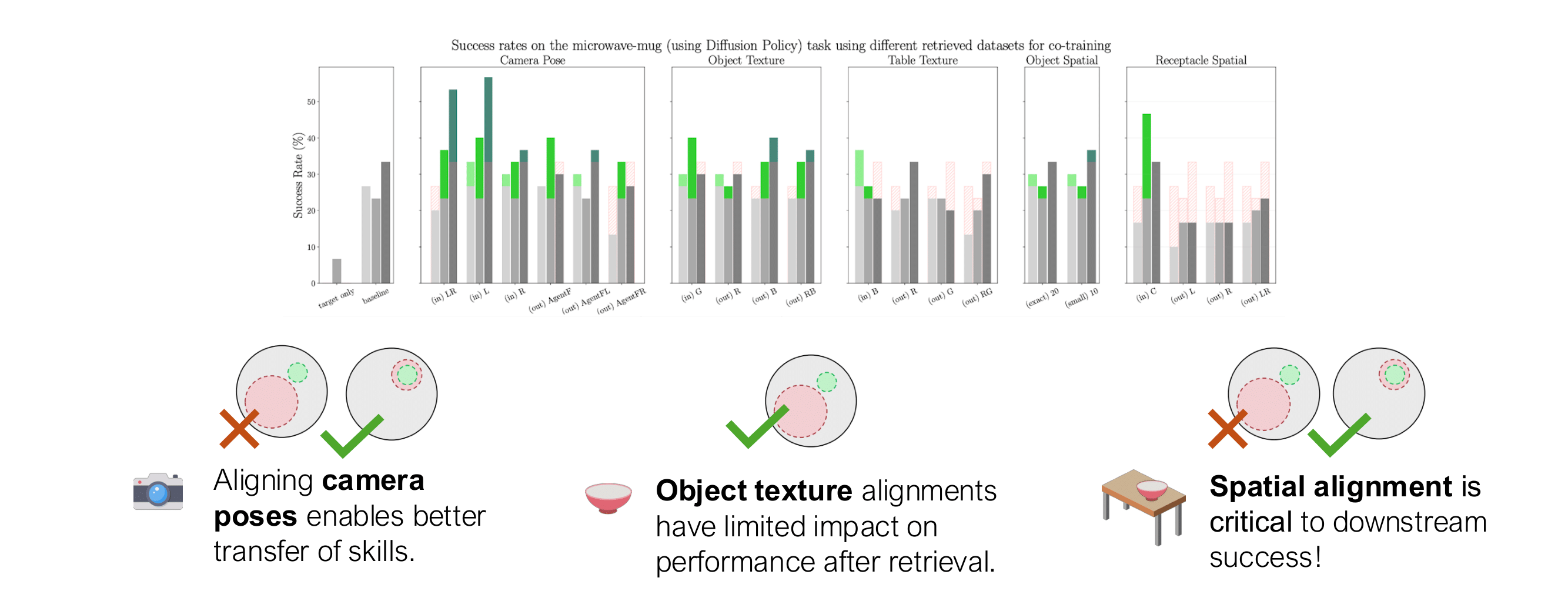
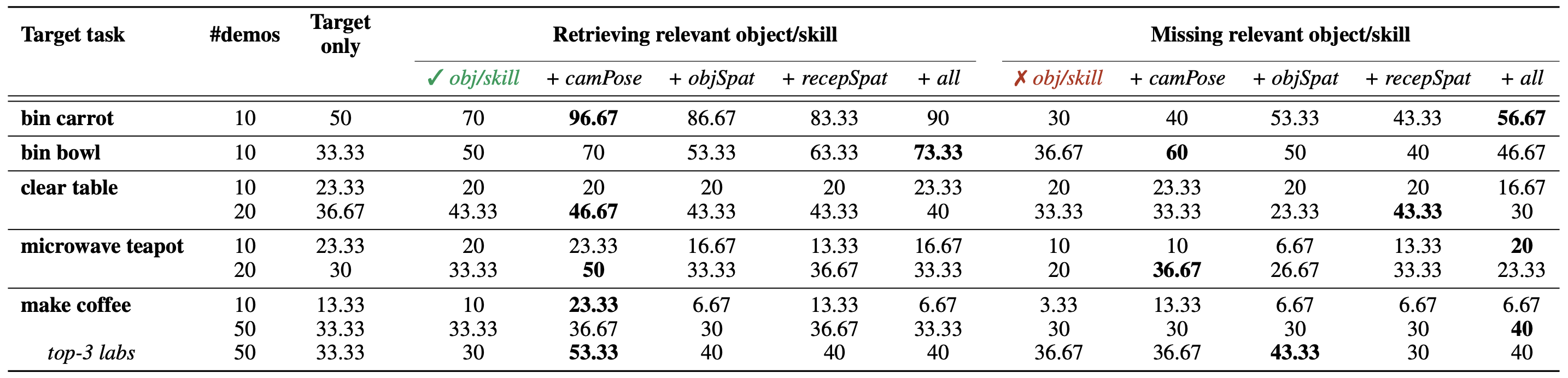
We summarize our findings in the table below, that shows success rates on all five target tasks shown above when co-training on different dataset splits in the MimicLabs dataset. Our structured demonstration generation pipeline allows for counterfactual retrival on the absence of the required skill for grasping the required object or accessign the receptacle.
@inproceedings{
title={What Matters in Learning from Large-Scale Datasets for Robot Manipulation},
author={Vaibhav Saxena, Matthew Bronars, Nadun Ranawaka Arachchige, Kuancheng Wang, Woo Chul Shin, Soroush Nasiriany, Ajay Mandlekar, Danfei Xu},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://arxiv.org/pdf/2506.13536}
}